How to block AI bots from scraping your site

Web security pro (stopped attacks on 2500+ sites). I help devs sleep at night. Building an open-source Web App Firewall for every framework (check it out at wafris.org)
AI use is exploding, with new services and use cases coming online daily.
What’s less well understood is where the underlying data that makes the AI models is coming from; the answer, in many cases, is your website.
Get the exact technical steps we use to identify AI bots from overrunning sites like yours.
We’ve helped stop attacks on over 2500+ sites like yours, and we’re the team behind the open-source web application firewall Wafris.
This guide will step you through the changes:
We recommend you make to your site today.
Give you a framework for making strategic decisions on what to do about AI bots specifically.
Show you the tools we’ve used to block millions of requests from harmful bots.
The Problem: AI Bots
FAANGs, Startups, and individual researchers are all furiously trying to gather as much data as possible from the web to feed the models they are building.
They’re getting this data from websites just like yours using web scraping bots that are unauthorized, in many cases unwelcome. What's worse is that in the process they pack your logs with noise and burn wild amounts of compute.
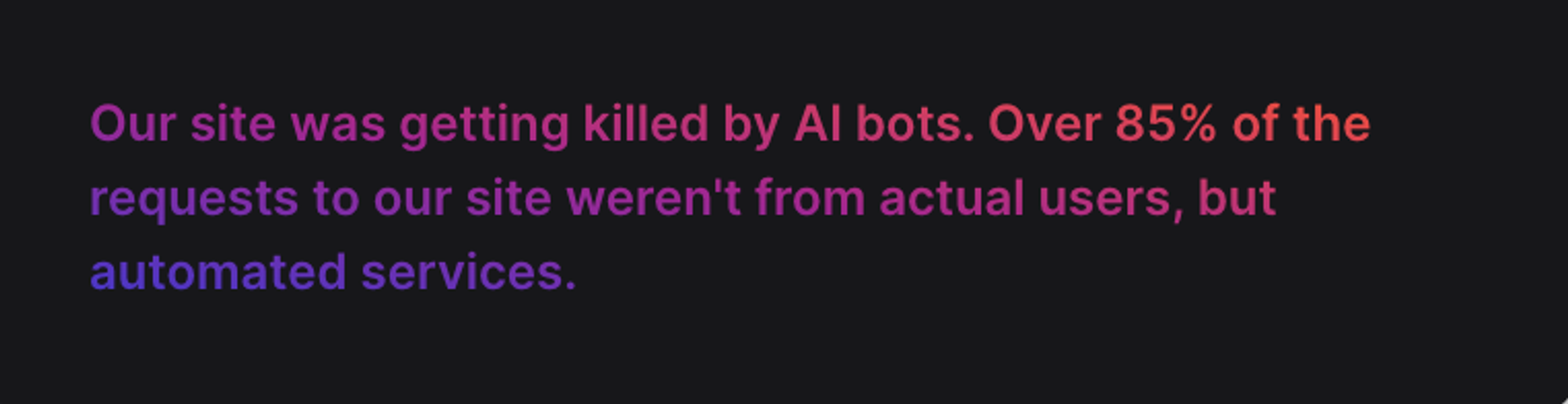
So should you block AI bot traffic?
Whether or not to block AI bots is a business and operational decision more than a technical one. Consider:
For a marketing company, it's likely a benefit that people can ask question of Chat GPT and get reasonable answers about your service. AI models are like mini search engines and in the same way you're happy to have Google index your site, you might be happy to have AI models index your site.
For a back office application, having AI bots scraping your site is a huge security risk and there's no beneficial use case for it.
For something in between - like an e-commerce site - it's a mixed bag. You might be happy to have AI bots index your site, but you might not want them to scrape your prices and product descriptions.
What we recommend
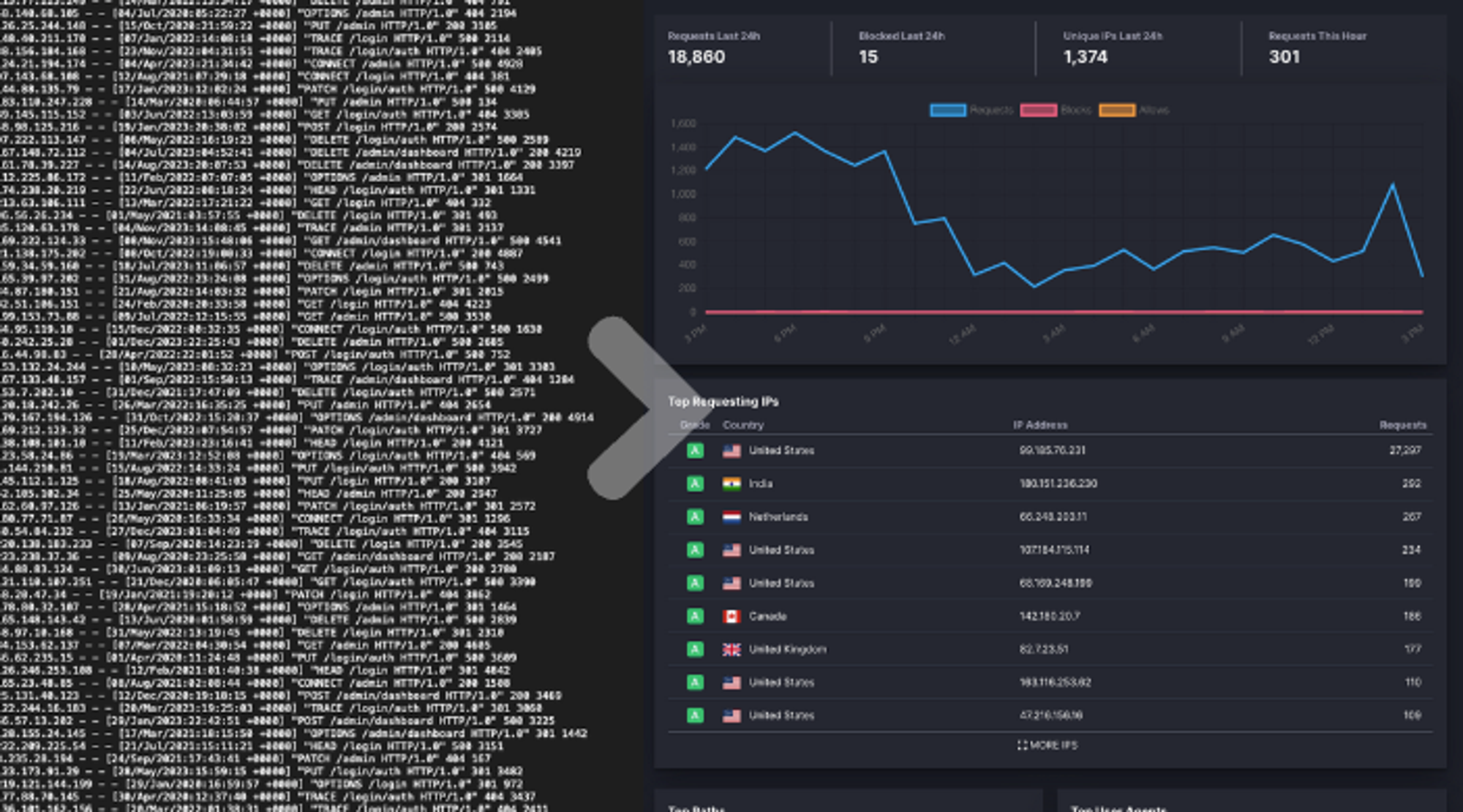
More than anything else we recommend understanding what's happening with the requests to your site. This is often a surprisingly difficult thing to do as the two most common windows into request data are logs and analytics, neither of which are particularly good at identifying bots.
The most important thing is to better understand what requests are actually hitting your site.
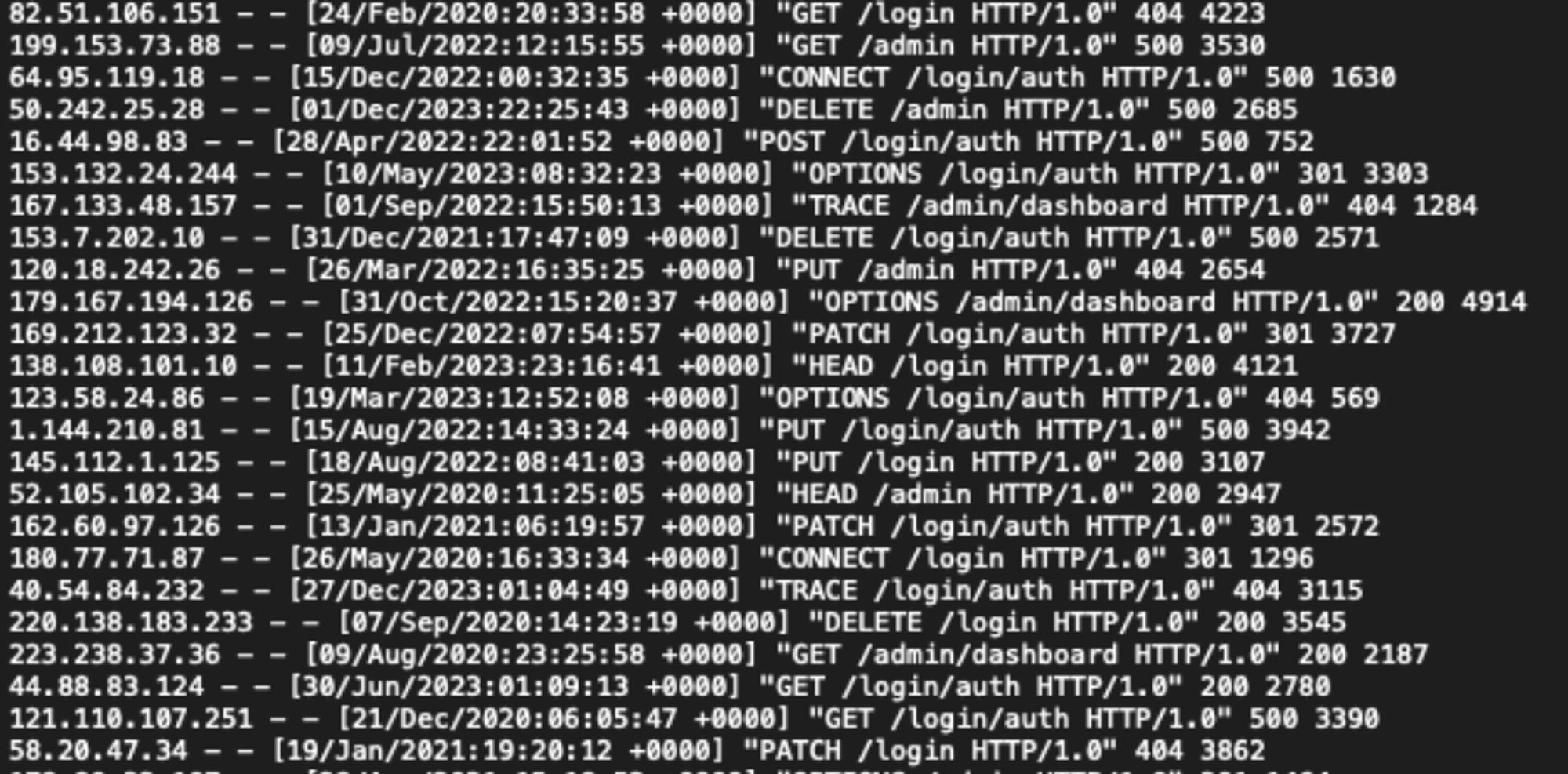
Logs
Logs are the most accurate source of request data, but they're also the most difficult to work with. They're often stored in a format that's difficult to query and when you can query them they still lack context about the request. ("Where is this IP from? What's this user agent represent?")
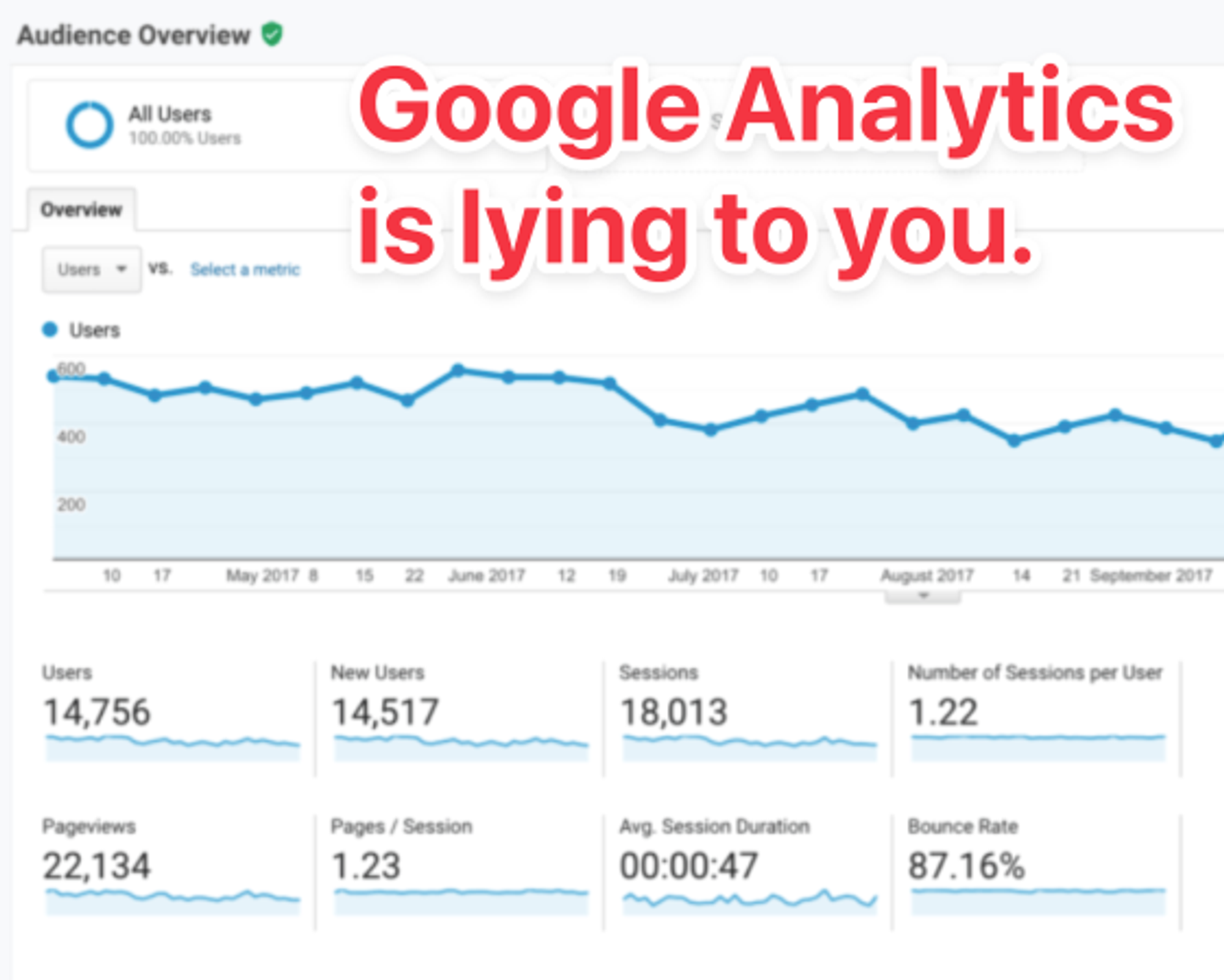
Analytics
Analytics are the most accessible source of request data, but they're also the least accurate. They're often based on JavaScript and cookies, which means they're easily fooled by bots.
Analytics tools are marketing tools and they're optimized for marketing use cases, which means doing their best to count real actual human visitors and deliberately filtering out bot traffic.
"We often see sites that receiving 20x more bot traffic than human traffic, and the analytics tools are often completely unaware of this."
Identifying Bots
"Bots" is a broad category that includes a wide variety of different types of automated activity.
Well Behaved Well behaved bots are bots that follow the rules, primarily this means that:
they identify themselves with a clear user agent
they respect
robots.txtdirectives.they rate limit themselves
Poorly Behaved Less repuatble bots are bots that don't follow these rules in what can be some infuriating ways. Most commonly, they'll ignore robots.txt and cloak themselves in a user agent that looks like a user in a browser.
These take extra work to identify and block, but it's typically worth it as they're the bots that are most likely to be highly disruptive.
Robots.txt
The robots.txt is a file placed in the root of a website that instructs bots and crawlers on how the site would like them to interact with it.
It’s the digital equivalent of a “Keep Out” sign - it will deter folks who obey the rules, but doesn’t offer any affirmative protection.

If your site should just not have any bots (AI, Search Crawlers, or otherwise), the following will request that they not make any requests against your site.
User-agent: *
Disallow: /
To more selectively disallow the most popular AI bots, add the following to your robots.txt.
# Perplexity.ai
User-Agent: PerplexityBot
Disallow: /
# Anthropic (Claude)
User-agent: anthropic-ai
Disallow: /
# Bytedance (TikTok)
User-agent: Bytespider
Disallow: /
# Common Crawl Bot
User-agent: CCBot
Disallow: /
# Apple AI Crawler
User-agent: Applebot
Disallow: /
# Meta Facebook Data
User-agent: FacebookBot
Disallow: /
# You.com
User-agent: YouBot
Disallow: /
# Google's Extended user agent (non search)
User-agent: Google-Extended
Disallow: /
# ChatGPT OpenAI
User-agent: GPTBot
Disallow: /
# Omigili
User-agent: omgili
Disallow: /
# Amazon (Alexa)
User-agent: Amazonbot
Disallow: /
Beyond politely asking that they keep out
Many bots disregard what’s set in a robots.txt file and whether out of malice or ignorance end up making punishing amounts of requests to your site.
To deal with these, we need a better set of tools:
1. Rate Limiting
Rate limiting is extremely effective at blocking bots as it doesn’t rely on identifying a particular bot, but on identifying the type of behaviors that identify bots.
Additionally, it’s just a good practice as whether or not the IP address making thousands of requests per minute of your site is precisely an “AI Bot” it’s not up to anything good.
2. Country Blocking
Bot makers rely on a series of proxies, VPNs, Tor networks and other means of cloaking their requests.
These aren’t free and the “best” of them are typically US based - by blocking countries you’re not doing business with you can pre-emptively stop attacks and increase the cost that a scraper would need to hit your site.
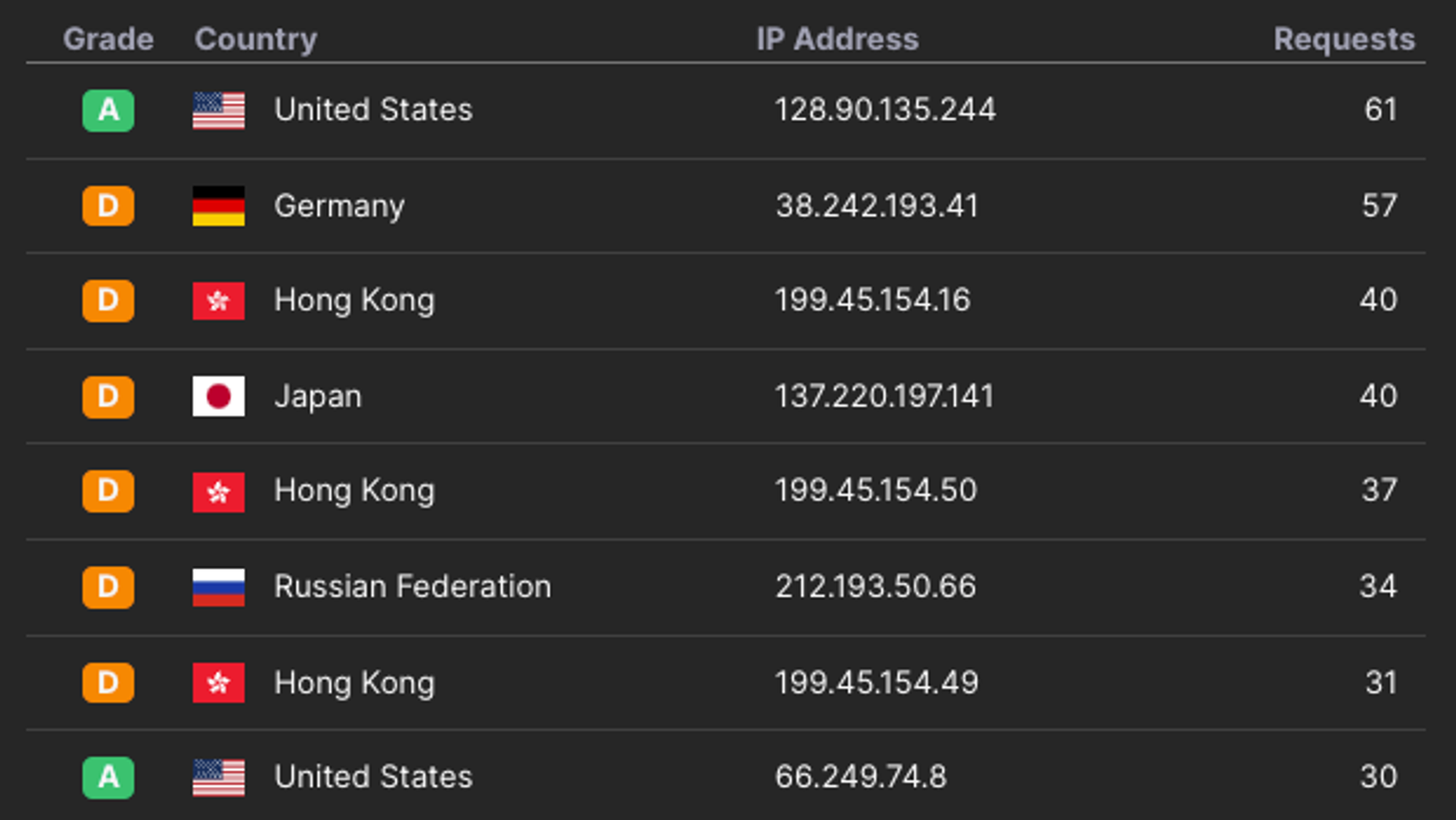
3. Reputation and Type Blocking
if you have a site that is used by people, it’s odd if an IP address from one of AWS’ data centers tries to access it. Similarly, there are well known web hosts that specialize in hosting spam and malware.
By categorizing where requests are coming from, and combining this with historical data like: “Yesterday. this same IP address attacked five other sites. So, today we should stop it from accessing our site.” you can shut down bots before they make a single request.
Here’s how we can help
We built Wafris to let sites:
Understand exactly what’s happening on their site in real-time
Automatically take steps to block bad bots of all kinds
Solve their security problems without hiring a whole new role.
Try it yourself at https://wafris.org or if you’d rather chat with an engineer, you can book a time at https://app.harmonizely.com/expedited/wafris